A useful script for enabling/disabling HD LEDs in a server running TrueNAS
If you happen to have a large storage array and are running TrueNAS, this script might come in handy. It makes it easy to turn on/off the LED lights associated…
If you happen to have a large storage array and are running TrueNAS, this script might come in handy. It makes it easy to turn on/off the LED lights associated…
Source: https://packetpushers.net/ubuntu-extend-your-default-lvm-space/ I didn't have to follow all that's in there so to keep it short, use these commands. Run this first: lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv Now, run this second command:…
Ever found your self looking for a way to add a group of users to a team site and one or more channels in bulk? I was in that situation…
I found an excellent article here that provided a nice PowerShell script to help automate the cleanup of Exchange related log files (tested on 2013/2016/2019). I made a few modifications…
I was looking for a why to bulk add a list of users into a Microsoft Teams Group however before I did that I wanted to compare the list of…
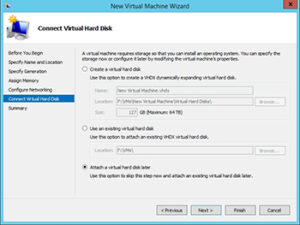
This is a repost from this article I recently created a large number of Hyper-V virtual machines as a part of an educational video series that I am about to…
If you are using SSSD to connect your linux box to AD then you might need to reset the cache that is used with mapping ids (uid and guid) to…
This is a repost from here Why use this method when you can deploy through the Azure Portal? The deployment of the Sophos XG firewall appliance through the new Azure…
If your like me you have a lot of backups, downloads, and/or copies files in various folders and cleaning it up and can be time consuming. To help with that…
This article is a repost from here Introduction UniFi Access Points (APs) and other devices are fantastic, but can be difficult to adopt from a UniFi Controller if they never…